Large Language Models (LLMs) such as GPT-3, BERT, and GPT-4 represent a significant advancement in the field of natural language processing (NLP). These models are designed to understand and generate human-like text, enabling a wide range of applications from chatbots and virtual assistants to automated content creation and language translation.
However, for LLMs to process and understand text effectively, they must first convert it into a format that the model can work with. This is where tokenization comes into play. Tokenization is the process of breaking down text into smaller units known as tokens, which can be words, subwords, or characters. This step is crucial for several reasons:
- Efficiency in Processing: Tokenization transforms text into manageable pieces, allowing models to handle and process large amounts of data efficiently.
- Context Management: Each token retains a piece of the context, enabling the model to generate coherent and contextually appropriate text.
- Handling Diverse Languages: Tokenizers can be adapted to different languages, dealing with various linguistic and morphological complexities.
- Optimizing Model Performance: Effective tokenization ensures that the most relevant information is processed within the model’s context window, enhancing overall performance.
In this article, we will delve into the necessity and future of tokenization in LLMs, exploring its current methodologies and future prospects, including integration with distributed ledger systems and the potential impact of quantum computing.
Why LLMs Need Tokenization
Efficiency in Processing:
Tokenization converts text into manageable pieces, making it possible for models to handle and process vast amounts of data. By reducing the text into smaller components, tokenization simplifies the complexity and helps in efficiently managing memory and computational resources. For instance, Byte Pair Encoding (BPE) is a commonly used algorithm that iteratively replaces the most frequent pair of bytes with a single token, thus reducing the sequence length while increasing the vocabulary size (ar5iv) (Coaches Wisdom Telesummit).
Context Management:
Tokenization helps in managing the context within the input data. Each token retains a piece of the context, allowing the model to understand and predict the next token based on the given sequence. This is crucial for generating coherent and contextually appropriate text (ChristopherGS).
Handling Diverse Languages:
Tokenizers can be adapted to different languages, handling linguistic variations and morphological complexities. While English tokenization might be straightforward, non-Latin languages pose challenges due to their unique scripts and grammar. Advanced tokenization techniques, such as subword tokenization, help in overcoming these challenges by breaking down words into smaller, meaningful units (Deepchecks).
Optimizing Model Performance:
Efficient tokenization contributes to better model performance by optimizing the use of the model’s context window. Different models have specific token limits (e.g., GPT-4 can handle up to 32,768 tokens), and effective tokenization ensures that the most relevant information is processed within these limits (Deepchecks).
Tokenization on a Distributed Ledger System
Tokenizing LLMs on a distributed ledger system, such as blockchain, introduces both opportunities and challenges:
Transparency and Trust:
A distributed ledger provides immutable and verifiable records of the tokenization process. This transparency can build trust in the integrity of the tokenization and the model’s outputs.
Decentralized Processing:
Distributed ledgers can enable decentralized tokenization, where multiple nodes participate in the process. This can enhance redundancy and resilience but might also introduce latency and performance overheads due to consensus mechanisms.
Privacy and Security:
Tokenizing sensitive text on a public ledger raises privacy concerns. Ensuring that data is encrypted and anonymized is crucial to protect user information while leveraging the benefits of decentralization.
Despite these potential benefits, the complexity and resource demands of integrating tokenization with distributed ledger systems make it a challenging proposition for large-scale applications (ChristopherGS).
Tokenization in the Quantum Era
Quantum computing promises to revolutionize many computational processes, including tokenization:
Enhanced Processing Power:
Quantum computers can process complex computations much faster than classical computers. This could make tokenization almost instantaneous, allowing for real-time processing of text data.
Advanced Algorithms:
Quantum algorithms might lead to new, more efficient methods for tokenization and natural language processing. These algorithms could handle larger datasets and more complex linguistic structures, potentially reducing the need for traditional tokenization.
Holistic Processing:
Quantum computing might enable models to process entire sentences or paragraphs as quantum states, bypassing the need for tokenization by allowing for more holistic and nuanced text analysis.
Improved Efficiency:
Quantum computing’s ability to manage high-dimensional data spaces could optimize tokenization, making it more efficient and reducing resource consumption.
While the future of quantum computing holds great promise, traditional tokenization methods will likely remain relevant until quantum computing becomes widely accessible and integrated into everyday NLP applications. For now, tokenization remains a crucial step in the functionality and performance of LLMs, ensuring that these models can effectively process and understand human language (ar5iv) (Coaches Wisdom Telesummit).
Examples and Case Studies
To illustrate the impact of tokenization on the performance of specific Large Language Models (LLMs) such as GPT-3 and BERT, let’s examine some concrete examples and case studies that highlight how different tokenization strategies influence their efficiency and effectiveness.
GPT-3 and Right-to-Left Tokenization
A study by Aaditya K. Singh and DJ Strouse evaluated the performance of GPT-3.5 and GPT-4 models on numerical reasoning tasks, revealing that tokenization direction significantly affects model accuracy. By enforcing right-to-left (R2L) tokenization using commas to separate digits, they observed improved model performance compared to the traditional left-to-right (L2R) tokenization. This method aligns the tokens of numerical data better with the expected output format, leading to fewer errors and enhanced computational efficiency. The findings suggest that tokenization strategies can introduce or mitigate inductive biases, which are crucial for numerical tasks (ar5iv) (Papers with Code).
BERT and Subword Tokenization
BERT, a model renowned for its bidirectional encoding, heavily relies on subword tokenization methods like WordPiece. This technique breaks down words into smaller units, allowing the model to handle out-of-vocabulary words more effectively. For instance, in multilingual contexts, subword tokenization helps BERT manage linguistic variations and morphological complexities across different languages. A comparative analysis by Bostrom and Durrett showed that subword tokenization outperformed character-level tokenization in tasks like part-of-speech tagging and neural machine translation, especially when fine-tuning BERT on specific datasets (ar5iv).
Improved Tokenization for Specific Domains
Research on specialized tokenization schemes has demonstrated their impact on domain-specific tasks. For example, character-level tokenization was found to be particularly effective for poetry classification tasks involving Arabic texts, outperforming subword tokenization methods. This approach ensures that each character is treated as a token, which is beneficial for handling the rich morphological structure of Arabic poetry (ar5iv).
Tokenization and Model Scalability
The scalability of LLMs like GPT-3 also depends on effective tokenization. As models scale, the need for efficient tokenization becomes more pronounced to manage the increased computational load. Subword tokenization methods, such as Byte Pair Encoding (BPE), balance the vocabulary size and sequence length, reducing memory usage and enhancing model performance. Jinbiao Yang’s research introduced the “Less-is-Better” (LiB) model, which autonomously learns an integrated vocabulary of subwords, words, and multiword expressions. This approach not only reduces the number of tokens but also improves the model’s adaptability and efficiency (ar5iv).
These examples underscore the critical role of tokenization in optimizing the performance and scalability of LLMs. By selecting appropriate tokenization strategies, researchers and practitioners can enhance the accuracy, efficiency, and overall functionality of these advanced models in various applications.
Real-World Applications of Tokenization
Tokenization plays a critical role in various industries, including healthcare, finance, and customer service, by enhancing data security, privacy, and operational efficiency. Here are some real-world applications that demonstrate the practical importance of tokenization:
Healthcare
In the healthcare industry, tokenization is used to protect patient data and ensure privacy while enabling valuable insights and improving patient outcomes. LexisNexis Risk Solutions’ Gravitas Network leverages next-generation tokenization technology to de-identify patient data and link disparate datasets, including genomics, lab results, and social determinants of health. This approach allows researchers and clinicians to gain more comprehensive and actionable insights, ultimately leading to better and more equitable patient care (HealthIT Today) (Healthcare Business Today).
Tokenization also plays a pivotal role in clinical trials and real-world evidence (RWE) studies. By creating unique patient identifiers that remain consistent across different datasets, tokenization helps prevent data duplication and enables precise data linkage. This not only improves study protocol design but also ensures more accurate tracking of patient progress and interactions with healthcare services. As a result, tokenization supports the advancement of precision medicine and the integration of diverse data sources for more inclusive clinical research (Marksman Healthcare) (Applied Clinical Trials).
Finance
In the finance sector, tokenization is increasingly used to enhance the security of financial transactions and digital assets. Tokenization converts sensitive information, such as credit card numbers or bank account details, into unique tokens that cannot be reversed. This process protects data from unauthorized access and reduces the risk of fraud. Additionally, tokenization facilitates the secure trading of real-world assets, such as real estate or commodities, on blockchain platforms, making transactions more transparent and efficient (ar5iv).
For instance, in digital payments, tokenization helps streamline transactions and improve security. Financial institutions and payment processors use tokenization to replace card information with tokens during online and mobile payments, ensuring that sensitive data is not exposed during transactions. This method has become a standard practice for enhancing the security of electronic payments and protecting consumer data (Papers with Code).
Customer Service
In customer service, tokenization aids in safeguarding customer information while enabling personalized interactions. For example, chatbots and virtual assistants utilize tokenized data to handle customer inquiries without exposing sensitive information. This allows companies to deliver efficient and secure customer service experiences. Furthermore, tokenization helps in maintaining customer privacy by ensuring that personal data, such as contact details or account information, is protected during customer interactions .
Tokenization also supports customer relationship management (CRM) systems by securely linking customer data across various touchpoints. By tokenizing customer identifiers, companies can create a unified view of customer interactions, enhancing their ability to deliver personalized and consistent service across multiple channels. This integration of secure data handling with customer service platforms improves overall customer satisfaction and loyalty (ar5iv).
These examples underscore the critical role of tokenization in enhancing data security, privacy, and operational efficiency across various industries. By adopting tokenization strategies, organizations can protect sensitive information, ensure compliance with regulatory standards, and provide better services to their customers.
Comparisons of Tokenization Techniques
Tokenization is a critical step in processing text for Large Language Models (LLMs). Here, we compare three popular subword tokenization techniques: Byte Pair Encoding (BPE), WordPiece, and SentencePiece, highlighting their pros and cons.
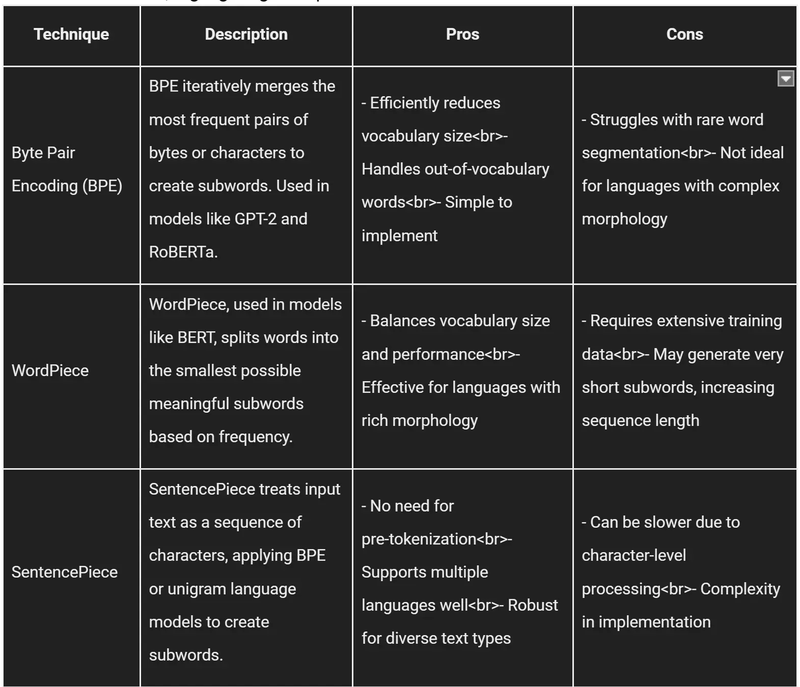
Byte Pair Encoding (BPE)
BPE is widely used due to its simplicity and efficiency. It starts with a base vocabulary of characters and iteratively merges the most frequent pairs to form subwords. This technique effectively reduces the vocabulary size and handles out-of-vocabulary words by breaking them into known subwords. However, BPE can struggle with rare words, leading to suboptimal segmentations, especially in languages with complex morphological structures.
WordPiece
WordPiece, employed by BERT, focuses on creating the smallest possible subwords that still maintain meaningful representations. It balances the vocabulary size and model performance by using frequency-based splits. WordPiece is particularly effective for languages with rich morphology. However, it requires a large corpus for training and may generate very short subwords, which can increase the sequence length and computational cost.
SentencePiece
SentencePiece, used in models like T5, treats the input text as a sequence of characters and applies either BPE or unigram language models to generate subwords. It eliminates the need for pre-tokenization and supports multiple languages efficiently. SentencePiece is robust for diverse text types, making it suitable for multilingual models. However, its character-level processing can be slower, and the implementation complexity can be higher compared to other methods.
Each tokenization technique has its strengths and weaknesses, making them suitable for different applications and languages. By understanding these differences, researchers and practitioners can choose the most appropriate tokenization method to optimize the performance of their LLMs.
Future Directions and Challenges in Tokenization
Tokenization, a fundamental step in natural language processing (NLP), continues to evolve with advancements in technology and increasing demands for accuracy and efficiency. Here we explore the future directions and challenges associated with tokenization, providing insights into ongoing research and potential breakthroughs.
Future Directions
Adaptive Tokenization Techniques:
Researchers are developing adaptive tokenization methods that can dynamically adjust to the context and language of the input data. These methods aim to improve the model’s ability to handle diverse linguistic structures and reduce the reliance on extensive pretraining datasets (ar5iv).
Cognitive Science-Based Approaches:
Inspired by cognitive science, new tokenization models like the “Less-is-Better” (LiB) tokenizer are being explored. These models aim to reduce the cognitive load by learning an integrated vocabulary of subwords, words, and multiword expressions. Such approaches promise more efficient tokenization by mimicking human language processing (MDPI).
Quantum Computing:
Quantum computing holds the potential to revolutionize tokenization by enabling real-time processing of text data. Quantum algorithms could provide new, more efficient methods for tokenization and natural language processing, potentially reducing the need for traditional tokenization techniques (ar5iv).
Challenges
Polysemy and Ambiguity:
Dealing with words that have multiple meanings (polysemy) remains a significant challenge. Tokenization models must discern context to accurately tokenize and interpret such words, which often requires sophisticated contextual understanding beyond current capabilities (MDPI).
Out-of-Vocabulary Words:
Handling out-of-vocabulary (OOV) words is another persistent issue. Subword tokenization techniques like Byte Pair Encoding (BPE) and SentencePiece help mitigate this by breaking unknown words into known subwords. However, these techniques can still struggle with very rare words and novel linguistic constructs (Hugging Face) (MDPI).
Language and Domain Adaptation:
Tokenization methods need to adapt to different languages and domains effectively. While current techniques perform well for widely studied languages like English, they often fall short for languages with complex morphology or less available training data. Ongoing research aims to create more universal tokenization methods that can be applied across various languages and specialized domains without significant performance loss (ar5iv) (MDPI).
Balancing Vocabulary Size and Performance:
Striking the right balance between vocabulary size and model performance is crucial. Larger vocabularies can capture more nuances but require more computational resources, whereas smaller vocabularies might lead to loss of meaningful information. Future tokenization techniques aim to optimize this balance to enhance model efficiency and accuracy (ar5iv) (MDPI).
Ongoing Research and Breakthroughs
Robustness and Resilience:
- Research is focusing on improving the robustness of tokenization methods to handle noisy and adversarial inputs. Techniques like CheckList, which provides a comprehensive framework for testing NLP models against various linguistic capabilities and test types, are being developed to ensure that tokenization models are resilient in real-world applications (ar5iv).
Integration with Multimodal Data:
- Integrating tokenization with multimodal data, such as combining text with images or audio, is another area of exploration. This integration aims to create more holistic models capable of understanding and generating complex, context-rich content across different media types (ar5iv).
Scalability and Efficiency:
- Enhancing the scalability and efficiency of tokenization methods remains a priority. Researchers are working on algorithms that can process larger datasets more quickly and with less computational overhead, which is essential for deploying NLP models in real-time applications (MDPI).
By addressing these challenges and leveraging ongoing research, the future of tokenization in NLP looks promising, with potential breakthroughs that could significantly enhance the capabilities of language models and their applications across various industries.
Expert Opinions and Quotes on Tokenization
Adding insights from experts in the field of NLP and tokenization provides valuable perspectives on the challenges and advancements in this area. Here are some expert opinions that highlight the significance and future directions of tokenization.
Insights from Researchers
Ajitesh Kumar, a notable expert in data science and machine learning, emphasizes the complexity and foundational nature of tokenization in NLP. He explains, “Tokenization is the process of breaking down a piece of text into small units called tokens. This foundational task is critical because every language has its unique grammatical constructs, making it challenging to create universal tokenization rules.” Kumar points out that while subword tokenization methods like Byte Pair Encoding (BPE), WordPiece, and SentencePiece have advanced the field, they still face challenges with handling out-of-vocabulary words and rare linguistic constructs (Analytics Yogi).
Future Directions
Researchers from the academic community, such as those contributing to a paper on tokenization techniques, suggest that future advancements may involve more adaptive tokenization methods. These methods could dynamically adjust based on the context and language of the input data, potentially improving the handling of polysemy and linguistic diversity (ar5iv). Additionally, the integration of cognitive science principles, such as the “Less-is-Better” (LiB) model, aims to create more efficient tokenization processes by mimicking human language processing (MDPI).
Challenges and Solutions
Venkat Gudivada, a professor of computer science, discusses the ongoing challenges in tokenization. He notes that dealing with polysemy (words with multiple meanings) and ensuring robustness against adversarial inputs are critical issues. Gudivada highlights the importance of developing tokenization techniques that can better handle these complexities by incorporating more sophisticated contextual understanding and robust testing frameworks (MDPI).
Robustness and Efficiency
A recent study on the robustness of NLP models emphasizes the need for tokenization techniques that can withstand noisy and adversarial inputs. The study calls for extensive testing and development of new tokenization algorithms that can adapt to various linguistic contexts while maintaining efficiency and accuracy. This includes exploring quantum computing’s potential to revolutionize tokenization by enabling real-time processing of text data (ar5iv) (ar5iv).
These expert insights underscore the critical role of tokenization in NLP and the ongoing efforts to address its challenges. By leveraging adaptive techniques and cognitive science principles, the field aims to enhance the efficiency and robustness of tokenization, paving the way for more advanced and reliable language models.
References and Further Reading
For readers interested in delving deeper into the topic of tokenization in Natural Language Processing (NLP), the following references and further reading materials provide comprehensive insights and detailed explanations:
- “Between Words and Characters: A Brief History of Open-Vocabulary Modeling and Tokenization in NLP” by Sabrina J. Mielke et al. (2021):
- This comprehensive survey covers the evolution of tokenization techniques and their applications in open-vocabulary modeling. It provides historical context and discusses various tokenization methods in detail.
- Read the survey on arXiv (Stanford CS324 Website).
- “Tokenization in NLP: Types, Challenges, Examples, Tools” on Neptune.ai:
- This article explores the importance of tokenization, different types of tokenization methods, and the challenges associated with them. It also discusses various tools used for tokenization in NLP projects.
- Read more on Neptune.ai (neptune.ai).
- “Transformers for Natural Language Processing and Computer Vision – Third Edition” by Denis Rothman (2024):
- This book provides an in-depth look at transformer models, including their architecture, capabilities, and practical implementations. It includes a section on tokenization as a critical preprocessing step in NLP.
- Find the book on O’Reilly (O’Reilly Media).
- “Tokenization in Natural Language Processing: An Essential Preprocessing Technique” on Spydra.app:
- This blog post outlines the role of tokenization in NLP, its applications, and the different tokenization techniques used to preprocess text data. It highlights the importance of tokenization in structuring textual data for further analysis.
- Read the article on Spydra.app (Spydra).
- “Tokenization and Text Data Preparation with TensorFlow & Keras” on KDnuggets:
- This guide provides practical examples of how to implement tokenization using TensorFlow and Keras. It covers various aspects of tokenizing training and testing data, as well as encoding and padding sequences for machine learning models.
- Explore the guide on KDnuggets (KDnuggets).
These resources offer a mix of theoretical foundations and practical implementations, making them valuable for both beginners and advanced practitioners in the field of NLP.
Conclusion
Tokenization is a vital process for LLMs, enabling them to efficiently handle and understand complex linguistic data. While distributed ledger systems and quantum computing present exciting possibilities, the practical implementation of these technologies in tokenization involves significant challenges. Nevertheless, the evolution of tokenization techniques continues to enhance the capabilities of LLMs, paving the way for more advanced and efficient natural language processing.

Leave a comment